ABSTRACT
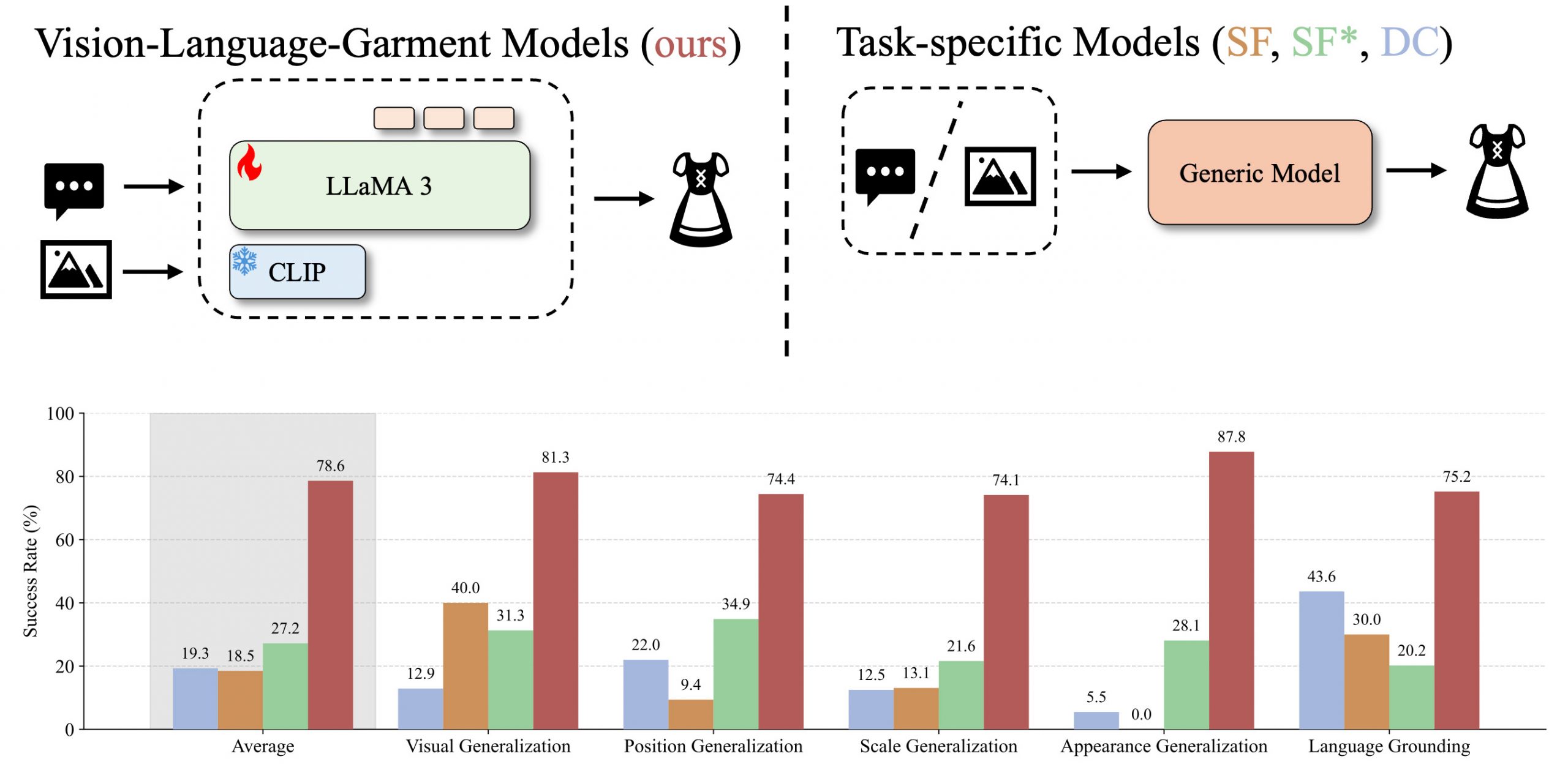
A vision-language-garment model is a multimodal foundation model for digital garments by fine-tuning a large multimodal model on a custom sewing pattern dataset using a novel tokenization scheme for these patterns. This approach transfers web knowledge to tasks requiring garment understanding a reasoning, enabling exciting new applications. Multimodal foundation models have demonstrated strong generalization, yet their ability to transfer knowledge to specialized domains such as garment generation remains underexplored. We introduce VLG, a vision-language-garment model that synthesizes garments from textual descriptions and visual imagery. Our experiments assess VLG’s zero-shot generalization, investigating its ability to transfer web-scale reasoning to unseen garment styles and prompts. Preliminary results indicate promising transfer capabilities, highlighting the potential for multimodal foundation models to adapt effectively to specialized domains like fashion design.