ABSTRACT
Generative models have shown great promise in synthesizing photorealistic 3D objects, but they require large amounts of training data. We introduce SinGRAF, a 3D-aware generative model that is trained with a few input images of a single scene. Once trained, SinGRAF generates different realizations of this 3D scene that preserve the appearance of the input while varying scene layout. For this purpose, we build on recent progress in 3D GAN architectures and introduce a novel progressive-scale patch discrimination approach during training. With several experiments, we demonstrate that the results produced by SinGRAF outperform the closest related works in both quality and diversity by a large margin.
FILES
CITATION
M. Son, J. J. Park, L. Guibas, G. Wetzstein, SinGRAF: Learning a 3D Generative Radiance Field for a Single Scene, CVPR 2023.
@inproceedings{son2023singraf,
author = {M. Son and J. J. Park and L. Guibas and G. Wetzstein},
title = {SinGRAF: Learning a 3D Generative Radiance Field for a Single Scene},
booktitle = {CVPR},
year = {2023},
}
Overview
 |
| SinGRAF generates different plausible realizations of a single 3D scene from a few unposed input images of that scene. In this example, i.e., the “office_3” scene, we use 100 input images, four of which are shown in the top row. Next, we visualize four realizations of the 3D scene as panoramas, rendered using the generated neural radiance fields. Note the variations in scene layout, including chairs, tables, lamps, and other parts, while staying faithful to the structure and style of the input images. |
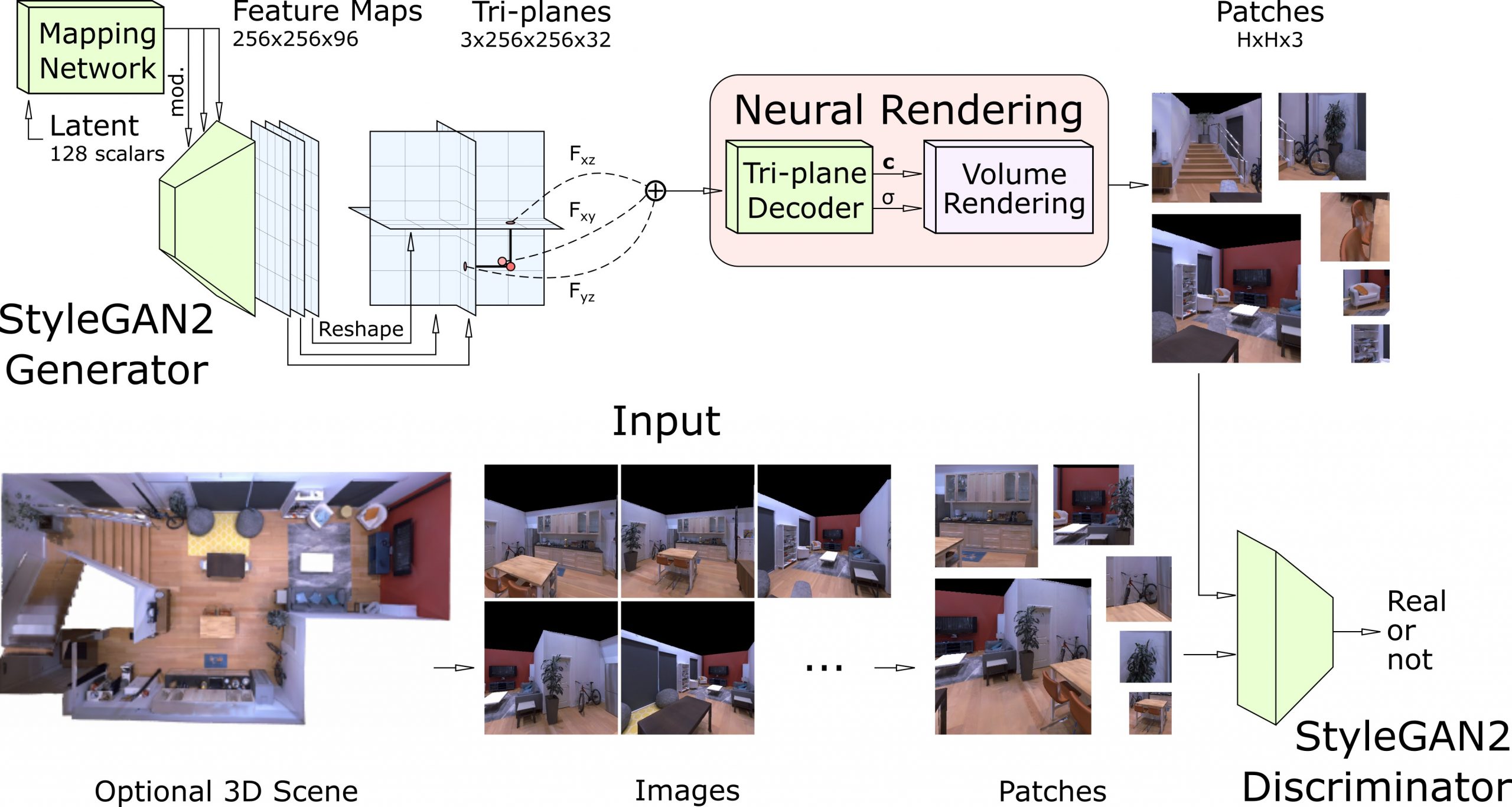 |
| SinGRAF pipeline. The framework takes as input a few images of a single scene, for example rendered from a 3D scan or photographed (bottom). The 3D-aware generator (top left) is then trained to generate 2D feature planes that are arranged in a triplane configuration and rendered into patches of varying scale (top right). These rendered patches along with patches cropped from the input images are then compared by a discriminator. Once trained, the SinGRAF generator synthesizes different realizations of the 3D scene that resemble the appearance of the training images while varying the layout. |